Exposed(DAO/DSL) で PostgreSQL からあれこれ SELECT するサンプル・覚書
記事の目的
自分が忘れないように!
create, update, delete は端折るけど、まあどうにかなるでしょう
もしかしたら N+1 の動きがちょっと怪しいかも
間違ってたら申し訳ないので使うときにはちゃんと確認して!
(数ヶ月がけでダラダラこの記事を書いてたら確認する気力が失せた)
補足
Table から取るやつが DSL, Entity が取るやつが DAO
今回の記事では JOIN したテーブルへの操作がメインだけど、JOIN なしのサンプルはこの記事がわかりやすい!
1:N のやつ
ついでに Enum も使う
DDL
ガバガバ
どういうテーブルか分かりにくいので、後続の Kotlin のコード見たほうが早いと思う
バンドとアルバムのテーブルがあって、バンドとアルバムが 1:N
create type country_enum as ENUM ('UK', 'US', 'JP'); create table if not exists bands ( id serial primary key not null, name varchar(50) not null, country country_enum not null ); create table if not exists albums ( id serial primary key not null, title varchar(50) not null, band_id serial references bands (id) not null, release_date date not null default current_date ); insert into bands(name, country) values ('Pink Floyd', 'UK'), ('Om', 'US'), ('筋肉少女帯', 'JP'); insert into albums(title, band_id, release_date) values -- Pink Floyd ('The Piper At The Gates Of Dawn', 1, '1967/8/5'), ('A Saucerful Of Secrets', 1, '1968/6/29'), -- Om ('Variations on a Theme', 2, '2005/2/14'), ('Conference of the Birds', 2, '2006/4/17'), -- 筋肉少女帯 ('仏陀L', 3, '1988/06/21'), ('SISTER STRAWBERRY', 3, '1988/12/21');
Exposed のサンプル
Table とか Entity の準備
// 列挙子はPostgreSQLのやつと揃えている!(揃えなくてもいけるけど!)
enum class Country { UK, US, JP }
// ExposedのEnumの使い方についてはこの辺をみて
// https://github.com/JetBrains/Exposed/wiki/DataTypes#how-to-use-database-enum-types
class PGEnum<T : Enum<T>>(enumTypeName: String, enumValue: T?) : PGobject() {
init {
value = enumValue?.name
type = enumTypeName
}
}
object BandsTable : IntIdTable("bands") {
val name = varchar("name", 50)
val country = customEnumeration(
name = "country",
sql = "country_enum",
fromDb = { value -> Country.valueOf(value as String) },
toDb = { it.name } // 上のコメントがここに関係してくる
)
}
class BandEntity(id: EntityID<Int>) : IntEntity(id) {
companion object: IntEntityClass<BandEntity>(BandsTable)
var name by BandsTable.name
var country by BandsTable.country
fun toModel(): Band =
Band(
id = id.value,
name = name,
country = country,
)
}
data class Band(
val id: Int,
val name: String,
val country: Country,
)
object AlbumsTable : IntIdTable("albums") {
val title = varchar("title", 50)
val band = reference("band_id", BandsTable)
val releaseDate = date("release_date").clientDefault{ LocalDate.now(ZoneId.of("Asia/Tokyo")) }
}
class AlbumEntity(id: EntityID<Int>) : IntEntity(id) {
companion object: IntEntityClass<AlbumEntity>(AlbumsTable)
var title by AlbumsTable.title
var band by BandEntity.referencedOn(AlbumsTable.band)
var releaseDate by AlbumsTable.releaseDate
fun toModel(): Album =
Album(
id = id.value,
name = title,
band = band.toModel(),
releaseDate = releaseDate,
)
}
data class Album(
val id: Int,
val name: String,
val band: Band, // Bandを持っちゃう!(持たないパターンは後述)
val releasedAt: LocalDate,
)
data class Band, Album はここ(Table, Entity のレイヤ)に置かなくてもサンプル的には問題ないけど、依存性とかそういう話を考えて今回は書く
使う
transaction { ... }やら@Transactionalのなかで...
単一テーブルから全部 SELECT
Entity からも Table からもとれるけど、Entity からのほうが楽
// band
val bandAllFromEntity: List<Band> = BandEntity.all().map { it.toModel() }
val bandAllFromTable: List<Band> = BandsTable.selectAll().map { BandEntity.wrapRow(it).toModel() }
// albumでも同様
// withがなくてもAlbum::bandに値が入るけど、N+1問題が出る
val albumAllFromEntity: List<Album> = AlbumEntity.all().with(AlbumEntity::band).map { it.toModel() }
// 逆にTableからの取得時にはスマートにeagerloadする方法が分からない
val album = AlbumsTable.innerJoin(BandsTable).selectAll().map {
BandEntity.wrapRow(it) // bandにもアクセスしておくとN+1起きなさそうだった
AlbumEntity.wrapRow(it).toModel() // 返すのはこっちだけ
}
単一テーブルから ID で 1 件 SELECT
BandID:2 の Om を取得する
これも Entity からも Table からもとれるけど、Entity からのほうが自明に楽
// 対象(ID:2)が確実に存在する場合
val omFromEntity: Band = BandEntity[2].toModel()
val omFromTable: Band =
BandsTable.select {
BandsTable.id.eq(2)
}.single().let { // 取る対象が明確に 1 件なら First(OrNull)じゃなくて Single(OrNull)のほうがいい
BandEntity.wrapRow(it).toModel()
}
// 対象(ID:2)が確実に存在するか分からない場合
val omFromEntity: Band? = BandEntity.findById(2)?.toModel()
val omFromTable: Band? =
BandsTable.select {
BandsTable.id.eq(2)
}.singleOrNull()?.let {
BandEntity.wrapRow(it).toModel()
}
単一/複数テーブルから where で指定して SELECT
まず JOIN が要らない Band テーブルのみを考えて name を指定して SELECT
これも Entity からも Table からもとれるけど、このあとの複数テーブルからの話を踏まえると Table からとっておいた方が楽になる場合が多い(改修の手間的に)
// 後々にJOINするならば
// おすすめしない
val floydFromEntity: Band? =
BandEntity.find {
BandsTable.name.eq("Pink Floyd")
}.singleOrNull()?.toModel()
// おすすめ
val floydFromTable: Band? =
BandsTable.select {
BandsTable.name.eq("Pink Floyd")
}.singleOrNull()?.let {
BandEntity.wrapRow(it).toModel()
}
80 年代のアルバムを SELECT
// 後々にJOINするならば
// おすすめしない
val eightiesFromEntity: List<Album> =
AlbumEntity.find {
AlbumsTable.releasedAt.greaterEq(LocalDate.of(1980, 1, 1))
.and(AlbumsTable.releasedAt.less(LocalDate.of(1990, 1, 1)))
}.with(
AlbumEntity::band
).sortedBy {
AlbumsTable.title
}.map {
it.toModel()
}
// おすすめ
val eightiesFromTable: List<Album> =
AlbumsTable
.innerJoin(BandsTable)
.select {
AlbumsTable.releasedAt.greaterEq(LocalDate.of(1980, 1, 1))
.and(AlbumsTable.releasedAt.less(LocalDate.of(1990, 1, 1)))
}.sortedBy {
AlbumsTable.title
}.map {
BandEntity.wrapRow(it) // ここも同上の理由で...
AlbumEntity.wrapRow(it).toModel()
}
次に Album テーブルと Band テーブルを JOIN した状態で name を指定して SELECT
これをやる場合には Entity からだと微妙で、Table からとる必要がある
val floydAlbumFromTable: List<Album> =
AlbumsTable
.innerJoin(BandsTable) // 忘れずに
.select {
BandsTable.name.eq("Pink Floyd")
}.sortedBy {
AlbumsTable.title
}.map {
AlbumEntity.wrapRow(it).toModel()
}
// There was an unexpected error (type=Internal Server Error, status=500).
// org.postgresql.util.PSQLException: ERROR: missing FROM-clause entry for table "bands"
// org.jetbrains.exposed.exceptions.ExposedSQLException: org.postgresql.util.PSQLException: ERROR: missing FROM-clause entry for table "bands"
val floydAlbumFromEntity: List<Album> =
AlbumEntity.find {
BandsTable.name.eq("Pink Floyd") //error
}.sortedBy {
AlbumsTable.title
}.map {
it.toModel()
}
// だめっぽい例
// こっちだと動くけど、N+1
val floydAlbumFromEntity: List<Album> =
AlbumEntity.wrapRows(
// ここでTable使うなら最初からDSLでいいよね
AlbumsTable
.innerJoin(BandsTable)
.select {
BandsTable.name.eq("Pink Floyd")
}
)
.with(AlbumEntity::band) //これ書いてもうまくeagerloadingされない
.sortedBy {
AlbumsTable.title
}.map {
it.toModel()
}
さっきの 80 年代アルバム取得の実装にバンド名を追加することを考えると、やっぱり Table からとっておいた方が楽
val kingShowEighties: List<Album> =
AlbumsTable
.innerJoin(BandsTable)
.select {
AlbumsTable.releasedAt.greaterEq(LocalDate.of(1980, 1, 1))
.and(AlbumsTable.releasedAt.less(LocalDate.of(1990, 1, 1)))
.and(BandsTable.name.eq("筋肉少女帯")) // 追加した行
}.sortedBy {
AlbumsTable.title
}.map {
AlbumEntity.wrapRow(it).toModel()
}
1:N のやつ(その 2)
DDL
上のと同じ
Exposed のサンプル
Table とか Entity の準備
基本上のと同じだけど、Album の Entity と Model だけ変更する
Table, Entity 的には Band と Album は関連してるけど、Model 上では切り離すような作りにしてみる
class AlbumEntity(id: EntityID<Int>) : IntEntity(id) {
companion object: IntEntityClass<AlbumEntity>(AlbumsTable)
var title by AlbumsTable.title
var band by BandEntity.referencedOn(AlbumsTable.band)
var releaseDate by AlbumsTable.releasedAt
fun toModel(): Album =
Album(
id = id.value,
name = title,
// band = band.toModel(),
band_id = band.id.value, //★ これ!
releaseDate = releaseDate,
)
}
data class Album(
val id: Int,
val name: String,
// val band: Band,
val band_id: Int, //★ これ!
val releaseDate: LocalDate,
)
使う
複数テーブルから where で指定して SELECT
何がしたいのかというと...こういうこと
data class Container(
val band: Band,
val albums: List<Album>
)
// 特に変えていないけど、見やすくするためにここにも書いただけ
data class Band(
val id: Int,
val name: String,
val country: Country,
)
data class Album(
val id: Int,
val name: String,
val band_id: Int,
val releasedAt: LocalDate,
)
val ukAlbumContainers = AlbumsTable
.innerJoin(BandsTable)
.select {
BandsTable.country.eq(Country.UK)
}.sortedBy {
AlbumsTable.title
}.map {
val band = BandEntity.wrapRow(it).toModel()
val album = AlbumEntity.wrapRow(it).toModel()
Container(band, album)
}
今回の例だと微妙(1:1 のオブジェクトでやったほうがいいかも)だけど、こんな感じに Model 間の依存関係を廃した場合、Table から select したあとの map で複数回 HogeEntity.wrapRow した結果を適当なオブジェクトに詰め込むといい
あとこのパターンだと N+1 が発生しなくて気が楽
中間テーブルを使って N:N のやつ
話が変わって N:N
参考:
DAO · JetBrains/Exposed Wiki · GitHub
set many-to-many relation using a DAO · Issue #347 · JetBrains/Exposed · GitHub
DDL
ガバガバ(上に同じく)
ユーザとコースのテーブルがあって、中間テーブルを介して N:N
テーブル自体はここのを参考にしている
やさしい図解で学ぶ 中間テーブル 多対多 概念編 - Qiita
create table if not exists users ( id serial primary key not null, name varchar(20) not null, email varchar(254); created_at timestamp not null default current_timestamp, updated_at timestamp not null default current_timestamp ); create table if not exists courses ( id serial primary key not null, language varchar(30) not null ); create table if not exists users_courses_relations ( id serial primary key not null, user_id serial not null references users (id), course_id serial not null references courses (id) ); insert into users(name, created_at, updated_at, email) values ('john', now(), now(), 'john@example.com'), ('bob', now(), now(), 'bob@example.com'); insert into courses(language) values ('HTML'), ('CSS'), ('Kotlin'), ('React'), ('Java'), ('C#'); insert into users_courses_relations (user_id, course_id) values -- John: HTML (1, 1), -- John: Kotlin (1, 3), -- Bob: HTML (2, 1), -- BoB: Kotlin (2, 2), -- Bob: React (1, 4);
Exposed のサンプル
Table とか Entity の準備
object UsersTable : IntIdTable("users") {
val name = varchar("name", 20)
val email = varchar("email", 254).nullable()
val createdAt = datetime("created_at").clientDefault{ LocalDateTime.now(ZoneId.of("Asia/Tokyo"))}
val updatedAt = datetime("updated_at").clientDefault{ LocalDateTime.now(ZoneId.of("Asia/Tokyo"))}
}
class UserEntity(id: EntityID<Int>) : IntEntity(id) {
companion object: IntEntityClass<UserEntity>(UsersTable)
var name by UsersTable.name
var email by UsersTable.email
var courses by CourseEntity via UserCourseRelations // ★ここがポイント
var createdAt by UsersTable.createdAt
var updatedAt by UsersTable.updatedAt
fun toModel(): User =
User(
id = id.value,
name = name,
email = email,
company = company?.toModel(),
courses = courses.map { it.toModel() }.toList(),
createdAt = createdAt,
updatedAt = updatedAt,
)
}
data class User(
val id: Int,
val name: String,
val email: String?,
val company: Company?,
val courses: List<Course>,
val createdAt: LocalDateTime,
val updatedAt: LocalDateTime
)
object CoursesTable : IntIdTable("courses") {
val language = varchar("language", 30)
}
class CourseEntity(id: EntityID<Int>) : IntEntity(id) {
companion object: IntEntityClass<CourseEntity>(CoursesTable)
var language by CoursesTable.language
fun toModel(): Course =
Course(
id = id.value,
language = language,
)
}
data class Course(
val id: Int,
val language: String,
)
object UserCourseRelations : IntIdTable("users_courses_relations") {
val user = reference("user_id", UsersTable)
val course = reference("course_id", CoursesTable)
}
使う
// EntityからID指定
val user = UserEntity[1].toModel()
// Entityから全部
val users = UserEntity.all().with(UserEntity::courses).map { it.toModel() }
// tableから名前指定
// すごくめんどくさいけど、こうするとN+1にならない
// 解決してね~ https://stackoverflow.com/questions/58586466/how-to-load-related-entities-in-jetbrains-exposed-dsl-approach
val johnBobFromTable =
UsersTable
.innerJoin(UserCourseRelationsTable)
.innerJoin(CoursesTable)
.select {
UsersTable.name.inList(listOf("John", "Bob"))
}.map {
UserVO(
id = it[UsersTable.id].value,
name = it[UsersTable.name],
email = it[UsersTable.email],
courses = emptyList(), // mapで差し替える
createdAt =it[UsersTable.createdAt],
updatedAt =it[UsersTable.updatedAt],
) to Course(
id = it[CoursesTable.id].value,
language = it[CoursesTable.language]
)
}.groupBy {
it.first
}.map { (_, pair) ->
val userVO = pair.first().first
val courseVOs = pair.map { it.second }
userVO.copy(courses = courseVOs)
}
おわりに
この記事をあてにしすぎず、Exposed 公式のリファレンスを読んだほうがいい!
Panasonic ジェットウォッシャーEW-DJ53の分解清掃メモ
あらすじ
汚れてきたし奥の方まで分解して清掃したい
取扱説明書には「電池の取り出し方」としてわかりにくい図が載っている
ご自分で分解した場合、防水機能が維持できず、故障する原因になります
パナソニックは分解するなと言っているので、どうなっても僕は責任を取りません!!
でもどう考えてもバラして清掃しないと耐えがたいと思う
内容
画像にまとめたので適宜拡大して見てね
多分、拡大表示してから「画像を新しいタブで開く」とかやると見やすい
すごくガサツなライティングをしていたため並べると苦しいものがある

ここまでバラすと部分部分にビビりながら慎重に漂白剤つけたりもできる(危なっかしいけど)
ついでに取扱説明書の手順だと基盤まで一気にぶっこ抜けているんだけど、僕がやったときには出来なかった気がした
ここから先の手順はまだ人知れず眠っている…… ピラミッドの隠し部屋のように……
C#でASP.NETばっか書いてた後にサーバサイドKotlinを使い始めて半年の感想
時系列順に
Rails と Go はあんまり好きじゃなかったので僕の母なる言語は C#にあると言っていい
ということで C#(ASP.NET)から Kotlin(SpringBoot)に移った感想を数年後にしみじみと楽しむために書いておく
IDE は VisualStudio から IntelliJ
リプレイスしたわけじゃなくて、転職しただけなのでそういう話は特にないし、
サーバサイドKotlinの話といいつつデプロイとかその辺作り込んでないからJVM言語だぜ!って話もない
因みに C#で使っていたバージョンは主に C# 7.3 で基本的に.NET Framework を使っていた...
.NET Core と C# 8.0 以降はほぼ趣味でしか触っていない
https://docs.microsoft.com/ja-jp/dotnet/csharp/whats-new/csharp-version-history
よいこと
data class が便利
data class で immutable に作れるので健全
便利な copy だの equal もついてくる
Kotlin
data class User(val id: Int, val name: String, private val hoge: String) {
fun show() = println("$id $name $hoge")
}
fun main(args: Array<String>) {
val user = User(1, "John", "xxx")
val user2 = user.copy(name = "Bob")
user.show() // 1 John xxx
user2.show() // 1 Bob xxx
}
C#
なげ〜〜!
public class User { public int Id { get; private set; } public string Name { get; private set; } private string Hoge { get; set; } public User(int id, string name, string hoge) { Id = id; Name = name; Hoge = hoge; } public void Show() => System.Diagnostics.Debug.WriteLine($"{Id} {Name} {Hoge}"); public User Copy(int? id = null, string name = null, string hoge = null) { var tmp = (User)MemberwiseClone(); tmp.Id = id ?? Id; tmp.Name = (name is null) ? Name : name; tmp.Hoge = (hoge is null) ? Hoge : hoge; return tmp; } } class Program { static void Main(string[] args) { var user = new User(1, "John", "xxx"); var user2 = user.Copy(name: "Bob"); user.Show(); user2.Show(); } }
プライマリコンストラクタ
最初戸惑った(後述)けど、慣れると楽
Kotlin
class User constructor(_id: Int, _name: String) {
val id: Int
val name: String
init {
id = _id
name = _name
}
}
// ↓省略したやつ
class User(val id: Int, val name: String)
C#
安心する長さ
public class User { public int Id { get; private set; } public string Name { get; private set; } public User(int id, string name) { Id = id; Name = name; }
NULL 安全
すごく健全に書ける
大変好ましい
Kotlin
val user: User? = null
// val user2: User = null // error!
// userがnullじゃない場合だけprint
user?.let {
println(it.name)
}
// userがnullならエラー
println(user?.name ?: throw Exception())
User user = null; // userがnullじゃない場合だけprint if (user is not null) System.Diagnostics.Debug.WriteLine(user.Name); // userがnullならエラー(ついでにnameも見る) if (user is not null && user.Name is not null) { System.Diagnostics.Debug.WriteLine(user.Name); } else { throw new Exception(); }
スコープ関数が便利
https://kotlinlang.org/docs/scope-functions.html
便利だしかっこいいと思うんだけど、会社では使わなくていいとして let 以外使わせて貰えない
(下手に使うとややこしくなるものは確かに多いけど...)
なんでもかんでも式
便利
Kotlin
// 三項演算子はないのでそこだけちょっと寂しく感じる
val x = if (true) { "ttt "} else { "fff" }
val user: User? = null
val y = user?.let { it.name + "さん" }
C#も 8.0 からは switch でそういうことできるようになってた
https://docs.microsoft.com/ja-jp/dotnet/csharp/whats-new/csharp-8#switch-expressions
when がなんだか便利
C#の switch よりなんか色々できる
https://kotlinlang.org/docs/control-flow.html#when-expression
Kotlin
val value = 10
val z = when {
value !is Int -> throw Exception()
value > 10 -> "10以上"
value == 10 -> "ぴったり10"
else -> "10より小さい"
}
LINQ っぽいのもちゃんとある
ここが大変わかりやすい
LINQ to Objects と Java8-Stream API と Kotlin の対応表 - Qiita
記載されている通り、素の状態だと kotlin.collections は LINQ っていうか Enumerable みたいに遅延でアレしてくれない
.asSequence()する必要がある
KotlinのListとSequenceって何が違うの? - Qiita
interface に既定の実装書ける
C#でも 8.0 から書けるのであんまり違いはない
https://docs.microsoft.com/ja-jp/dotnet/csharp/whats-new/csharp-8#default-interface-methods
拡張メソッドもある
https://kotlinlang.org/docs/extensions.html
Kotlin
data class User(val id: Int, val name: String)
class Util {
companion object {
fun User.callName() = println(name + "さん!!")
}
}
fun main(args: Array<String>) {
val user = User(1, "Taro")
user.callName()
}
public class User { public int Id { get; private set; } public string Name { get; private set; } public User(int id, string name) { Id = id; Name = name; } } public static class Util { public static void CallName(this User user) => System.Diagnostics.Debug.WriteLine(user.Name + "さん!!"); } class Program { static void Main(string[] args) { User user = new User(1, "xxx"); user.CallName(); } }
Enum がなんだかすごく便利
すごく便利!!
https://kotlinlang.org/docs/enum-classes.html
enum class Dog(val id: Int, val japaneseName: String, val origin: String) {
SHIBA(1, "柴犬", "日本"),
GOLDEN_RETRIEVER(2, "ゴールデンレトリバー", "?" ),
SAMOYED(3, "サモエド", "ロシア");
fun show() = println("$id $japaneseName $origin")
}
fun main(args: Array<String>) {
val dog = Dog.values().first { it.japaneseName == "柴犬" }
dog.show() // 1 柴犬 日本
val dog2 = Dog.valueOf("GOLDEN_RETRIEVER")
dog2.show() // 2 ゴールデンレトリバー ?
}
C#
めんどくさいので端折った
public enum Dog: int { SHIBA = 1, GOLDEN_RETRIEVER = 2, SAMOYED = 3, } public static class DogUtil { public static void Show(this Dog dog) { // 本当はDisplay attributeとかでいい感じに... object result = dog switch { Dog.SHIBA => "1 柴犬 日本", Dog.GOLDEN_RETRIEVER => "2 ゴールデンレトリバー ?", Dog.SAMOYED => "3 サモエド ロシア", _ => throw new NotImplementedException(), }; System.Diagnostics.Debug.WriteLine(result); } class Program { static void Main(string[] args) { // kotlinのdog相当はDisplay attributeとかでいい感じに... var dog2 = Enum.GetValues(typeof(Dog)).Cast<Dog>().First(x => x.ToString() == "GOLDEN_RETRIEVER"); dog2.Show(); } }
SpringBoot 自体ではそんなに困らない
そんなに使いにくいとかは感じない
コアな実装をそんなしていないから気づかないだけかも...
開発者を集めやすいっぽい
Java みたいなもんだしね
混乱したこと
コンストラクタと init
最初はすごく混乱する
return 書かなくてもいい
inline function の reified
いまだにこれが必要な仕組みがよく分かっていない
型引数をあれこれして難しいことをしようとするときに登場する
https://kotlinlang.org/docs/inline-functions.html#reified-type-parameters
好きじゃないこと
gradle がマジで意味分からん
Kotlin の言語仕様イイヨネとかいう以上に gradle が嫌いで僕はまだ C#の方が好き
よくわからんエラー吐くし... 依存性の解決面倒くさすぎるし... IntelliJ との噛み合わせも完璧というわけではないし...
その点 C#では全部 MS が作ってたからその辺の気持ち悪さは一切なかった
Nuget 返して
でも gradle はビルドということでなんでもかんでも出来るのは便利!
とはいえ個人的にはライブラリ周りとビルド周りは別のモジュールとして管理された方が親切じゃない?!と思っている...
public がデフォルト
やだ~
総評
Kotlin 自体は C#よりも書いていて楽しい
でも gradle が苦行で辛い
僕は Rails を恐怖・忌避しているけど、gradle への気持ちの大きさはそれに比肩する
今後の課題
- gradle を渋々勉強する
- 難しいコアな実装をする
- 認証とかエラーハンドリングとか CSRF とかそういうの
localstackでsqsとlambda(kotlin)を動かしたりlog4j2とslf4jでログ吐くサンプル
概要
タイトルがおおよそ全て(ラノベ)
localstackでAWS SQS, Lambdaをつくる
SQSとLambdaを紐付ける
shellscriptでSQSにメッセージを送り、LambdaはSQSからメッセージを吸い上げて起動する
※ SQSなしでLambda単体をつくり起動するパターンもつくった
Lambdaのfunctionはkoltinで書いてロギングはLog4j2とSlf4j
gradle(groovy)で頑張る
ついでにLambdaの単体テストもJUnit5で書いた
コード
https://github.com/0mmadawn/localstack-sqs-lambda
だいたいこれ読めばわかるのであんまり書くことがないけど一応メモ
大変だったこと
- Log4j2とSlf4jのことなんも知らなかった
- Log4jとLog4j2の違いも知らんかった
- gradleがよくわからない(深刻に)
- localstackのログ出力がよくわからない
- 最終的にLS_LOGではなくてDEBUGの方で解決させたけど、特にそのへん設定せず親切にログが出ると思っていると痛い目を見る
- とにかく最初からエラーの物量がたくさんだった
- 最終的にもよくわからないエラーがいくつかあった
- 小さい状態から徐々に大きくしたほうがいい...(仕事ではそうもいかなかった)
参考
リポジトリに書いてあるのは省略
Lambdaいろいろ
- https://docs.aws.amazon.com/lambda/latest/dg/with-sqs.html
- https://docs.aws.amazon.com/lambda/latest/dg/java-logging.html
- https://docs.aws.amazon.com/lambda/latest/dg/java-handler.html
- https://github.com/aws/aws-lambda-java-libs
Log4j2 + Slf4j
- https://stackoverflow.com/questions/48033792/log4j2-error-statuslogger-unrecognized-conversion-specifier
- https://github.com/aws/aws-lambda-java-libs/tree/master/aws-lambda-java-log4j2
- https://github.com/awsdocs/aws-lambda-developer-guide/tree/main/sample-apps/java-basic
- https://stackoverflow.com/questions/49973441/logging-using-log4j2-on-aws-lambda-class-not-found/49973486#49973486
- https://qiita.com/NagaokaKenichi/items/9febd2e559331152fcf8
- https://kagamihoge.hatenablog.com/entry/2015/01/20/212230
- https://www.nextdoorwith.info/wp/se/slf4j/
Lambdaのテスト
JUnit 5
【SQL】関連しない複数テーブルをそれぞれSELECTした結果を使ってinsertしたい
前提
この記事のテーブル構成を丸パクリ!(名前ちょっと違うけど)
- coursesテーブル
- id
- language
- usersテーブル
- id
- name
- courses_user_relationsテーブル
- id
- user_id
- course_id
こういう感じのテーブル構成で
courses_user_relationsテーブルに
insert into courses_user_relationsテーブル(user_id, course_id) values (1, 1);
じゃなくて
insert into hoge(text, user_id) values ( select id from user where name = 'john' limit 1, select id from courses where language = 'HTML' limit 1 );
みたいなことしたい
で、PostgreSQLを使うことにする
結論
cross joinを使う
WITH U AS (SELECT id AS user_id FROM users WHERE name = 'john' LIMIT 1), B AS (SELECT id AS course_id FROM courses WHERE language = 'HTML' limit 1) INSERT INTO courses_user_relations(user_id, course_id) SELECT user_id, book_id FROM U, B ;
SELECT user_id, book_id FROM U, B 部分は
SELECT user_id, book_id FROM U CROSS JOIN BでもOK
FROM T1 CROSS JOIN T2はFROM T1, T2と同じです。 また(後述の)FROM T1 INNER JOIN T2 ON TRUEとも同じです。
https://www.postgresql.jp/document/9.2/html/queries-table-expressions.html
よもやま
普通にバックエンド処理の中でこれやるならusersやらcoursesを縛る値はロジックの中で取り回してるでしょ?と想像すると思う、
今回なんでこれがしたかったかというと、Migrationファイルで中間テーブルにデータ入れる時にはそうもいかないので... という話だったのだ
だいたいこれでいけるボソボソにならず生クリームも使わない楽なカルボナーラ
ふとカルボナーラを作ろうと思った
参考にしたレシピ動画
正直僕のレシピよりこっち見たほうがいい
- Ropiaシェフ: イタリアンのシェフ【カルボナーラ】徹底解説
- Ropiaシェフ, 大西哲也シェフ: 【徹底比較】イタリアンのプロとカルボナーラの作り方を比べてみた!【パスタ】【chef Ropiaさんコラボ】Vol.86
- Ropiaシェフ, 大西哲也シェフ: プロ2人がカルボナーラ徹底比較【COCOCOROチャンネルさんコラボ】
- 日高良実シェフ: 【シェフのパスタ料理】ASMR料理!日高良実思い出のカルボナーラ2種をご紹介します
- 落合務シェフ: 落合務シェフ直伝!簡単で美味しいカルボナーラの作り方 【シーガイア~Smile for Hope~】
- 奥田政行シェフ: 世界3位が作る究極のカルボナーラ 詳細レシピ 秘伝のコツ 全て教えます 奥田政行シェフ
Ropiaシェフが一番Youtube慣れしているのもあって、氏のレシピを見ると一番わかりやすい
材料
一覧
- パスタ: 150g (2人前くらい?)
- ベーコンorパンチェッタorグアンチャーレ: 60gくらい(多ければ多いほど嬉しい)
- 塩: ちょっと(茹で汁用)
- オリーブオイル: ちょっと(肉の油出し用)
- ソース
- 卵3つ: (全卵+卵黄*2)
- 黒胡椒: 好きなだけ
- パルミジャーノ: 20-30gくらい
- パスタの茹で汁: 30-50ccくらい
- 仕上げ
- 黒胡椒: 好きなだけ
- パルミジャーノ: ちょっと
生クリームはなし
材料のポイント
肉類
カルボナーラは素材の味が云々とは多くの人が言ったもので、肉はよいものを使うべきだとされる
でもパンチェッタとグアンチャーレは高いのでベーコン(デカめ)で十分でしょう
鎌倉ハムのブロックベーコンあたりが有力候補か
パンに挟むような薄いベーコンでもいいと思うけど多分寂しい
http://www.kawajiya.jp/item/272/
自分でパンチェッタもといパンチェッタもどきの塩豚を作るのもあり
一番安くできる
レシピでも記載するけど、肉の油を出してソースに利用するのでハムだと辛そう
卵
カルボナーラは素材の味が云々の件に従って卵も良いものを使うといいんだろうけど高いので僕はこだわらない
全卵+卵黄*2がポイント
生クリームを買いたくないけどソースをある程度かさ増ししたい!という要求に答えるのがこの構成になる
詳しくは後述の「ソースをボソボソにしないように」を参照
リッチにもう1個全卵or卵黄追加してもいいけど150gのパスタに対してはこの量で不満な感じはしない
パスタを200gくらいにするなら(全卵+卵黄)*2くらいでもいけたはず
卵白は捨てずにコップにでも逃して冷蔵保存しておく
何かしらまともなレシピに使のがいいんだけど、僕は別途適当なチーズ(ちぎったスライスチーズで十分)と混ぜてフライパンで焼くことで名もないオヤツを作っている
チーズ
既製品の粉状のパルメザンを使うからよくわからない味になる
パルミジャーノ・レッジャーノかグラナ・パダーノを使うこと
後者の方が安い
パルメザンとパルミジャーノの違いは各々調べてください
付録:OKストアの値段を自分用にメモしてある
- OKストア
- グラナパダーノ(zanetti 18ヶ月熟成) 200g 税込509円(OK会員現金価格)
- パルミジャーノ(zanetti 24ヶ月熟成) 200g 税込682円(OK会員現金価格)
パルミジャーノを20g使うとおよそ68円という計算になる。高いね~
ついでにチーズグレーターに関しては以下を使っている
https://www.amazon.co.jp/gp/product/B00151WA06/
由緒正しいものでないと目詰まりなどが辛いらしいが初手でこれを買ったので、安い製品の使い勝手は知らない
ただ、このチーズグレーターは長すぎる
下でチーズを受けるボウルにある程度の大きさがないと高級なチーズが飛び散ってしまうので注意
レシピ
内容
僕はアルデンテとかそういうものがよくわかってないので気をつけるように
- ベーコンを切っておく
- なんでもいいけど短冊切り派が多いみたい
- ボウルに卵とソースの材料をいれ混ぜる
- 空気を入れるように/入れないように という流派があるようだけど僕は深く考えてない
- パスタ用のお湯を用意する
- お湯には塩を入れる. 味噌汁にしてはちょっとしょっぱいくらいがいいと聞いた
- 火を入れる前のフライパンにちょっとオリーブオイルを垂らし、火を入れる前からベーコンを設置して弱~中火で加熱しソテー
- 油が出てジュワジュワ言い出したらパスタを茹で始める
- (ここで一旦手が空くのでちょっとだけ洗い物をする)
- パスタが茹で上がる1分前くらいに茹で汁を規定量フライパンに移す
- この工程によって事前にベーコンとその油と茹で汁を馴染ませておく(らしい)
- 後で足してもいいので茹で汁は少なめだと安心
- パスタをフライパンに移して弱火~中火でちょっと加熱
- 僕はこの工程なくてもいいんじゃないかと思っている
- フライパンの火を消して恐る恐るソースを入れ混ぜる
- 卵に火が通りすぎないようフライパンの火を消すのがポイント!
- 様子を見ながらちょっとだけ弱火で加熱し、ちょっとまとまりが出たら火を止めて予熱で加熱
- ここでソースをもうちょい伸ばしたければ茹で汁をちょっと足す
- お皿に盛り付ける
- トングを使う。皿着地タイミングでトングをくるっとひねった後、そのまま着地させるとキレイ
- 仕上げに黒胡椒をまぶす、ブルジョワジーはチーズもまぶす
- それぞれパスタからはみ出て、パスタの乗っていない皿の余白部分にちょっとかかるくらいが上品
レシピのポイント
ベーコンをカリカリに
ベーコンをカリカリにするのをついついやりすぎる事が多い
ベーコンがちょっとカリカリになってきたか...?くらいでパスタを茹で始めておくと丁度よい気がする
同時進行にする必要のない優雅な人はカリカリにしたあと火を止めて放置しておいて、それからパスタを茹で始めた方が気持ち楽
ソースをボソボソにしないように
ソースが固まってボソボソになる原因は主に卵白
全卵を使わず卵黄だけを利用する理由はそこ
生クリームを入れるのも同じような感じ
尚且、強く火を入れすぎるとそれによってすぐ火が入っちゃうのでそこも難しい
日高良実シェフは丁寧に湯煎で火入れしてるけど、僕はめんどくさいのでそこまでしない
ソースはパスタを入れる前派・後派それぞれで派閥が分かれるみたいだけど、個人的には後の方がボソボソになりにくいと思う
おわりに
カルボナーラは簡単だけどこれをひとつ勉強するだけで他に活かせる知識がたくさん身につく
2022年はカルボナーラをつくろう
【React】【Cognito】AWS CognitoのSMS MFA認証を試す(割と親切記事)
あらすじ
表題の件を試すには正直言ってAWS Amplifyあたりを使うのが賢いと思う
でもいきなり便利なものを使って泥臭い方法を知らないまま進むと大概苦しむことになるわけで、それはシステムが僕の首に描いた数々の索条痕が証明している
地道にやる
やることの概要
- バックエンド(AWS)をTerraformでつくる
- Cognitoにユーザを追加する
- フロントをReactでつくる
- ID:PW入れたらSMSが飛んできて、そのPINを入力すると認証通る!というとこだけ
- ユーザ作成とかPW再設定とかはサボる
- いざSMS MFA
バックエンド(AWS)の構築
AWS Cognitoを使う
今回必要なリソースはTerraformでつくった
gistに投げてあるので参考に
sample terraform file for creating AWS Cognito (MFA) · GitHub
sms_role_ext_idとかパスワードポリシーとかセッションタイムアウトとか、自分のものに変えるように
これで以下の通りリソースを作る
- MFAでSMSを送るIAMロール
- CognitoのUserPool
- CognitoのUserPoolのクライアント
- CognitoのIdentityPool
- 認証がOKな場合のIAMロール※
- 認証がNGな場合のIAMロール※
- CognitoのIdentityPoolと認証OK/NG用IAMロールの紐付け
ここで作ったリソースのIDやらをフロント側で利用することになる
Cognitoにユーザを追加
追加
・ユーザ追加はAWS Consoleでやる(極力サボりたいので)
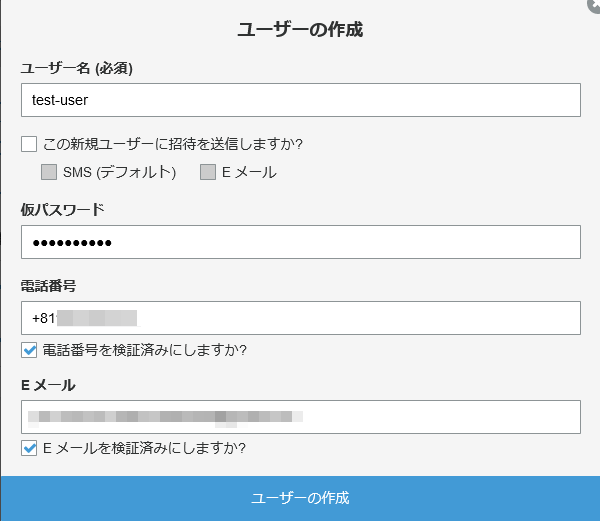
Terraformで構築したユーザプールにユーザを作る
その際に特に気をつけたいこと: ユーザが日本にいるならその電話番号は国コード+81を頭につけておかないとダメ
例えば090-1234-5678ならば+819012345678
初期パスワードはパスワードポリシーに沿ったもの
メールアドレスは今回使わないんだけど、Cognitoの構築時にメール必須にしちゃったから入れた(うっかり)
この状態だとアカウントのステータスがFORCE_CHANGE_PASSWORDのままなので認証を通す必要がある
認証
初回認証
認証というか、よくある「本人確認のついでに初期パスワードを変更してください」というやつの対応をする
今回は初期パスワードをもう一回入力して使い回す
# 変数にUSERNAME使ったリするとOSの環境変数とぶつかったりして怖い気がする AUTH_USERNAME='test-user' USER_POOL_ID='ap-northeast-XXXXXXXXXXX' CLIENT_ID='XXXXXXXXXXXXXXXXXXXXXXXXXX' AUTH_PASSWORD='XXXXXXXXXX' aws cognito-idp admin-initiate-auth \ --user-pool-id ${USER_POOL_ID} \ --client-id ${CLIENT_ID} \ --auth-flow ADMIN_USER_PASSWORD_AUTH \ --auth-parameters "USERNAME=${AUTH_USERNAME},PASSWORD=${AUTH_PASSWORD}" \ > result-admin-initiate-auth.txt # これどっかの記事を参考にしたと思うんだけど見つからなかった... SESSION_ID=`cat result-admin-initiate-auth.txt | grep Session | cut -d ":" -f 2 | tr -d '"' | tr -d ' ' | sed '$s/.$//' ` aws cognito-idp admin-respond-to-auth-challenge \ --user-pool-id ${USER_POOL_ID} \ --client-id ${CLIENT_ID} \ --challenge-name NEW_PASSWORD_REQUIRED \ --challenge-responses "USERNAME=${AUTH_USERNAME},NEW_PASSWORD=${AUTH_PASSWORD}" \ --session ${SESSION_ID}
参考:プログラミングせずにCognitoで新規ユーザー登録&サインインを試してみる | DevelopersIO
この時点でアカウントのステータスはCONFIRMEDに変化し、ついでに指定した電話番号に「認証コードは ****** です」というSMSが飛んでくる
が今回の目的は初回認証だったのでこれは無視
因みにこれ+この続きの中で出てくる --auth-flow ADMIN_USER_PASSWORD_AUTH という形で指定する認証方式が重要で、ここで指定したものはCognito側の設定で許可しておく必要がある
折角なのでCLIでSMS認証
上記のスクリプトとほぼ同じだけどちょっと違うので注意
AUTH_USERNAME='test-user' USER_POOL_ID='ap-northeast-XXXXXXXXXXX' CLIENT_ID='XXXXXXXXXXXXXXXXXXXXXXXXXX' AUTH_PASSWORD='XXXXXXXXXX' # admin-initiate-authじゃなくてinitiate-auth aws cognito-idp initiate-auth \ --auth-flow USER_PASSWORD_AUTH \ --client-id ${CLIENT_ID} \ --auth-parameters "USERNAME=${AUTH_USERNAME},PASSWORD=${AUTH_PASSWORD}" \ > result-admin-initiate-auth.txt
でSMSが送られてくるので...
# PINに差し替え SMS_MFA_CODE='XXXXXX' SESSION_ID=`cat result-admin-initiate-auth.txt | grep Session | cut -d ":" -f 2 | tr -d '"' | tr -d ' ' | sed '$s/.$//' ` # admin-respond-to-auth-challengeじゃなくてrespond-to-auth-challenge aws cognito-idp respond-to-auth-challenge \ --client-id ${CLIENT_ID} \ --challenge-name SMS_MFA \ # MFA! --challenge-responses \ USERNAME=${AUTH_USERNAME},SMS_MFA_CODE=${SMS_MFA_CODE} \ --session ${SESSION_ID}
成功するとこんな感じのレスポンスが返ってくる
{ "ChallengeParameters": {}, "AuthenticationResult": { "AccessToken": "xxxxx", "ExpiresIn": 300, "TokenType": "Bearer", "RefreshToken": "xxxxx", "IdToken": "xxxxx" } }
ここのIdTokenがよくいうjwt tokenというもの
他に何も変えてないけど色々試してたら急にSMS送られなくなったんだけど?!という場合、クォータの問題だったりするかも
フロントの構築
Reactを使う
create-react-appを使って足場をつくり、スタイリングはbulmaでガサツにやる
実現していることは
・ID:PW入れたらSMSが飛んできて、そのPINを入力すると認証通る!というとこだけ
・ユーザ作成とかPW再設定とかはサボる
これだけ
具体的にやっていることはReadMeとかコード見たほうが早いかも
React周辺で至らぬところがありそうでごめんなさい
動き的には、認証が必要なページ(/)があって、そこへのアクセス時に認証が済んでなければ(/login)に飛ばしてログインさせる感じ

認証後にはjwt_tokenというのを表示するとこまでやっている
この辺参考になるかも:
Cognitoのサインイン時に取得できる、IDトークン・アクセストークン・更新トークンを理解する | DevelopersIO
Cognitoを使う場合、最終的にはこのトークンを用いてAPI Gateway(AuthorizerにCognito)に認証付きのリクエストを飛ばすことになるはず
でも今回はAPI Gatewayのリソースつくるの面倒くさいから端折った
import useSWR from 'swr'
// ...
async function fetcher(url: string, jwt_token: string) {
// ここでトークンを指定!
const res = await fetch(url, { headers: { Authorization: jwt_token } });
const json = await res.json();
return json;
}
// どっかから拾ってくる
const jwt_token = token;
const API_URL = 'YOUR API GATEWAY ENDPOINT';
const { data, error } = useSWR([API_URL, jwt_token], fetcher);
if (error) return <div>failed to load</div>;
if (!data) return <div>loading...</div>;
const result = JSON.parse(data.body);
// resultをあれこれ...
あとデザインはここのを参考にさせていただいた
おわりに
大変だった
参考にしたもの
全般
こちらはjQueryで実現している
今回Reactを使いたかった(というよりjQueryを使いたくなかった...)からコードはそこまで参考にしていないけど、それ以外のCognitoにまつわる全体的な話は超参考にさせていただいた
こっちは素Nodeでコードをだいぶ参考にさせていただいた
Cognito + API Gateway
Amazon Cognito と仲良くなるために歴史と機能を整理したし、 Cognito User Pools と API Gateway の連携も試した | DevelopersIO
Amazon API Gateway をクロスオリジンで呼び出す (CORS) | DevelopersIO
Amazon API GatewayでAPIキー認証を設定する | DevelopersIO
API GatewayのオーソライザーにAmazon Cognitoを使ってみた件 - サーバーワークスエンジニアブログ
Terraform
【AWS】TerraformでCognitoをつくって楽したいんだ! | Katsuya Place
フロントのコードの参考
node.js - 'AWSCognito' is not defined - Stack Overflow
Reactでroot importする方法 - React(リアクト)でコンポーネント(Component)を呼ぶ時(import)、rootフォルダーを基準にして参照できるように設定して見ます。
amazon-cognito-identity-jsがセッション情報をsessionStorageに保存できるようになった - Qiita